Advanced Video QA System
End-to-end RAG desktop pipeline allowing users to chat with local video files using LLMs, vector search, and precise timestamp navigation.
Executive Overview
The Advanced Video QA System is a state-of-the-art desktop application that completely revolutionizes interactions with long-form video content. By implementing a highly specialized Retrieval-Augmented Generation (RAG) pipeline, it allows professionals to literally "chat" with local video files, receiving highly accurate answers linked directly to actionable, playable timestamps.
The Problem Statement
"Extracting specific information from multi-hour video content (like university lectures, corporate town halls, or legal depositions) requires tedious manual scrubbing. This results in massive losses in productivity and makes video a highly inefficient medium for rapid knowledge retrieval."
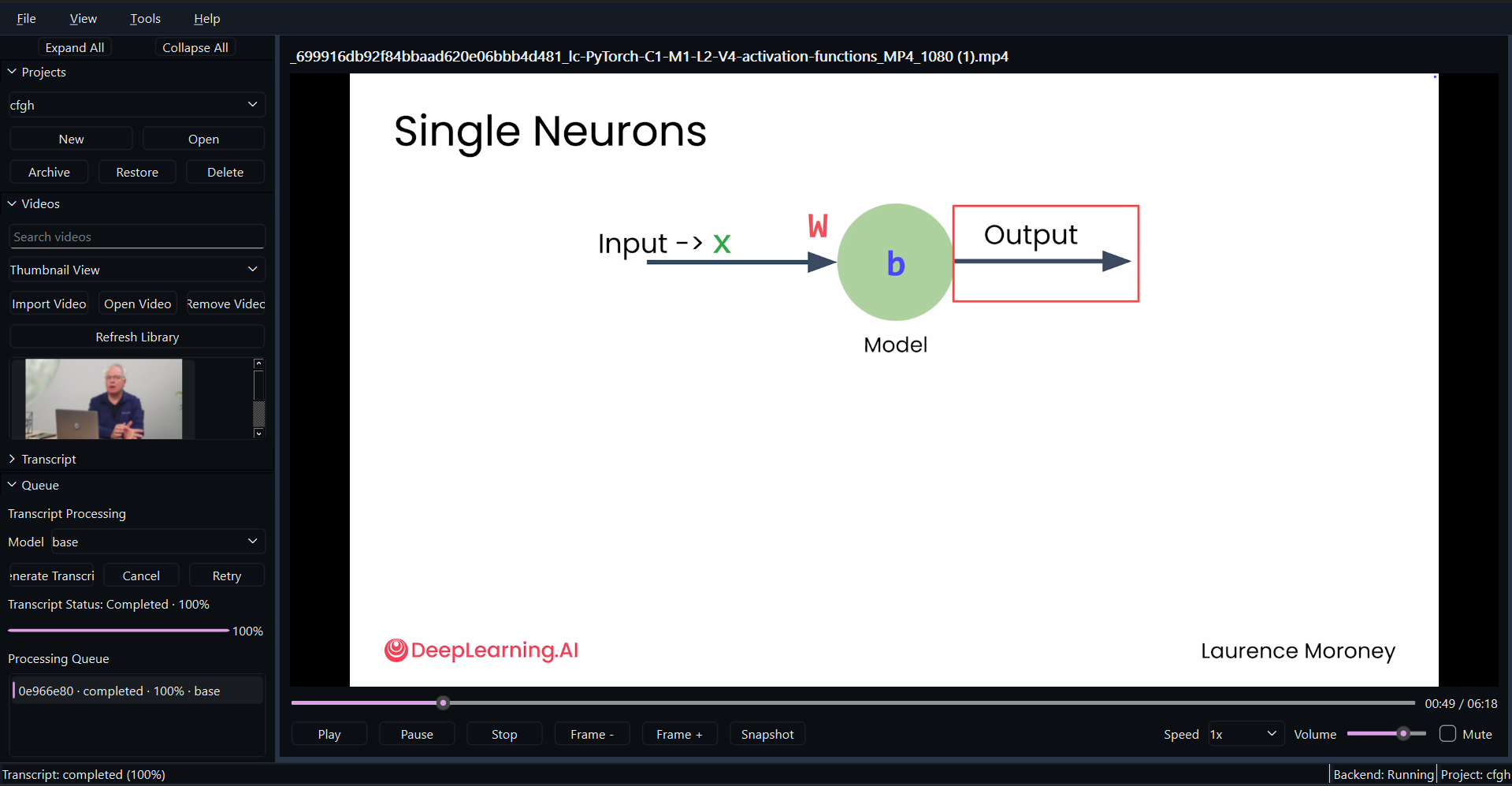
System Architecture
Technical Challenge
Connecting semantic text retrieval to exact video timestamps required building a custom data structure. Standard RAG pipelines lose temporal context during the chunking phase. Additionally, processing gigabytes of video locally via FFmpeg and Whisper required robust local resource management to prevent CPU thermal throttling.
Engineered Solution
The application is built on PyQt6 for a highly responsive, native desktop experience. The ingestion pipeline utilizes FFmpeg to strip audio, which is processed by OpenAI Whisper to generate timestamped transcripts. We built a custom LangChain document loader that preserves temporal metadata (start/end seconds) within the Document objects. These are embedded using OpenAI ADA-002 and stored in a local FAISS vector database. During querying, the LLM synthesizes an answer and strictly returns the temporal metadata, which the PyQt frontend uses to instantly seek the embedded video player to the exact relevant frame.
Extended Visuals
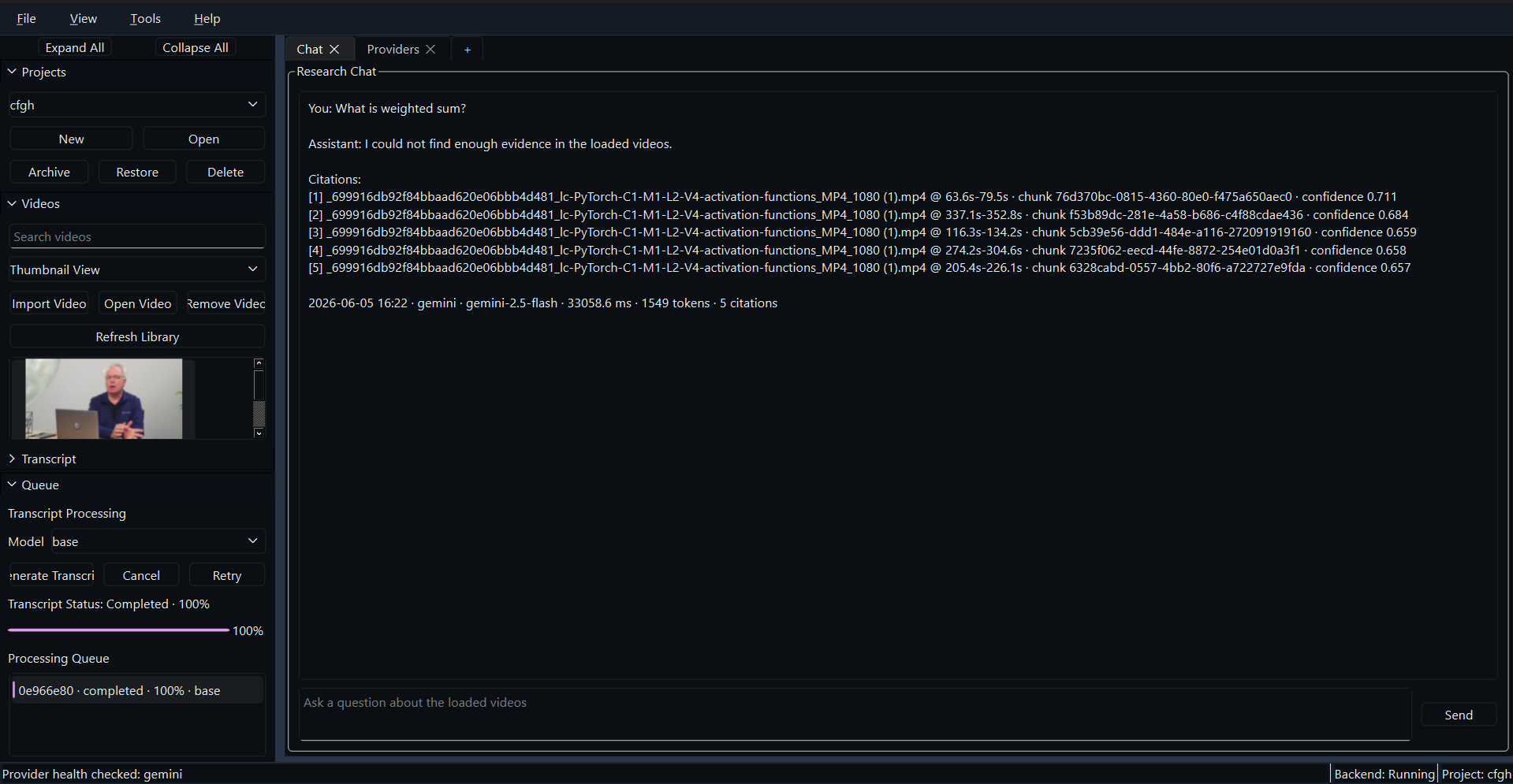
Critical Engineering Decisions
Custom Temporal Chunking Strategy
Standard recursive text splitters destroy the timeline. We engineered a custom chunking algorithm that splits transcripts by time-windows (e.g., 30-second blocks with 5-second overlaps), ensuring every vector embedding is mathematically tied to a specific video segment.
Local FAISS over Cloud Vector DBs
To guarantee absolute privacy for sensitive local video files and ensure zero latency during the retrieval phase, we opted to serialize FAISS indices directly to the local filesystem rather than relying on external vector databases like Pinecone.
Future Technical Roadmap
- 1Implement multi-modal RAG using LLaVA to query the actual visual frames of the video, rather than just the transcribed audio track.
- 2Add local LLM inference via Ollama to create a 100% air-gapped system requiring zero internet connectivity.
Core Capabilities
- Automated, high-accuracy audio extraction and Whisper transcription
- Temporal-aware semantic chunking and local FAISS vector storage
- Context-aware conversational querying utilizing GPT-4
- Instant GUI-to-Video timestamp seek functionality
- Local-first architecture ensuring proprietary corporate videos never leave the machine
Technology Stack
Business Impact
- Reduced specific information retrieval time in 2-hour videos from an average of 15 minutes to under 3 seconds
- Enabled semantic, natural-language search across entire local video libraries seamlessly
- Achieved a fully self-contained desktop architecture deployable to enterprise environments
Need something similar?
We specialize in architecting custom ai systems and automation pipelines tailored to exact enterprise specifications.
Request Architectural Proposal